动态智能抽取器
新增一个动态智能抽取器
在星原Studio图形化界面中,点击增加一个“自定义模型”
在弹出的选择窗口中选择“智能抽取器”并点击下一步
自定义输入一个抽取器的名称(建议按照需要抽取的样本或抽取的信息命名,便于后期管理使用)
系统将会自动完成配置,等待几秒钟,完成后点击下一步,并点击完成即可
完成以上步骤后,将进入动态智能抽取器初始化界面,在该界面,我们可以看到动态智能抽取器的使用文档,此时,点击最上边“开始”章节的“上传一个PDF文件或者图片”。
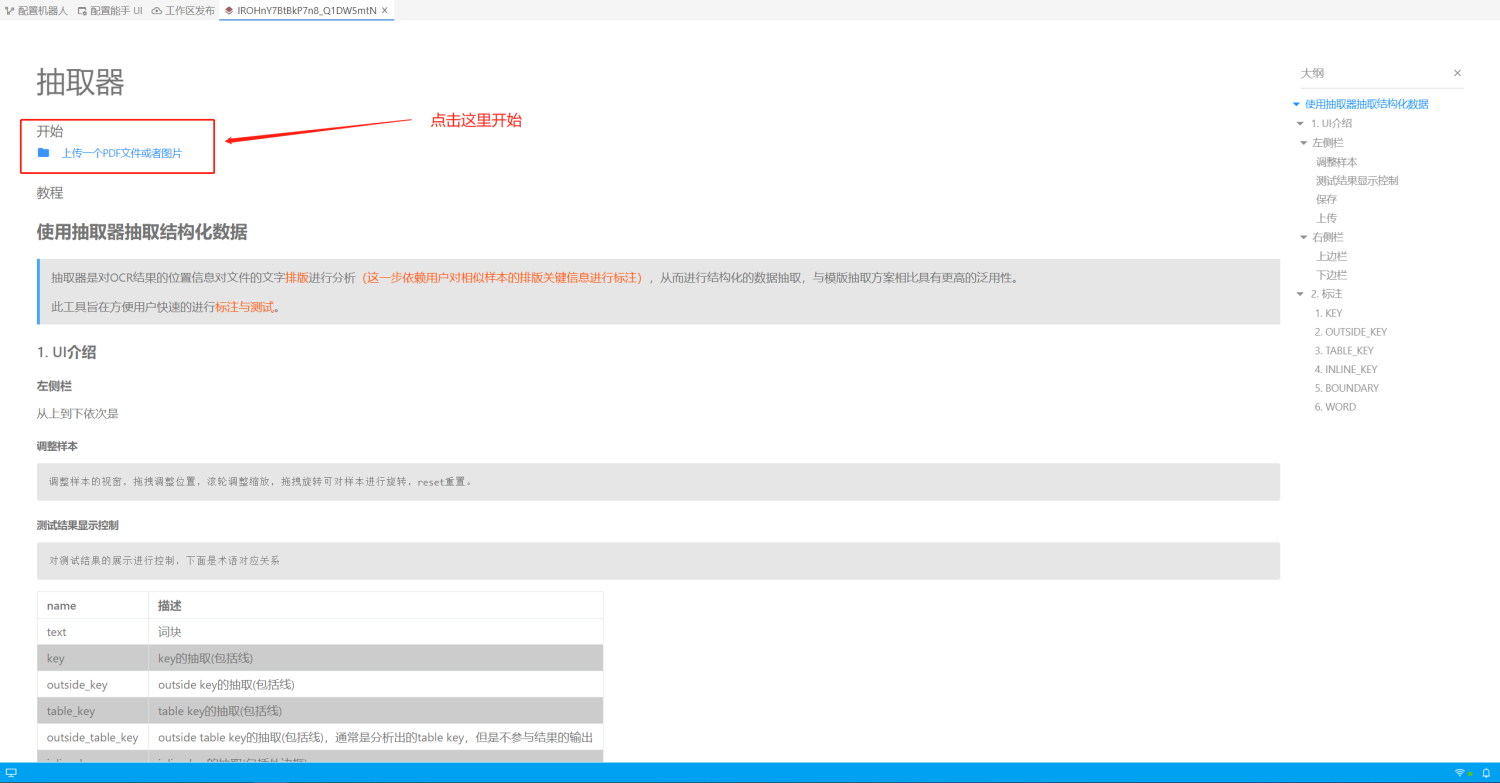
使用抽取器抽取结构化数据
抽取器是对OCR结果的位置信息对文件的文字排版进行分析(这一步依赖用户对相似样本的排版关键信息进行标注),从而进行结构化的数据抽取,与模版抽取方案相比具有更高的泛用性。
此工具旨在方便用户快速的进行标注与测试。
1. UI介绍

左侧栏

从上到下依次是
调整样本
调整样本的视窗,拖拽调整位置,滚轮调整缩放,拖拽旋转可对样本进行旋转,reset重置。
测试结果显示控制
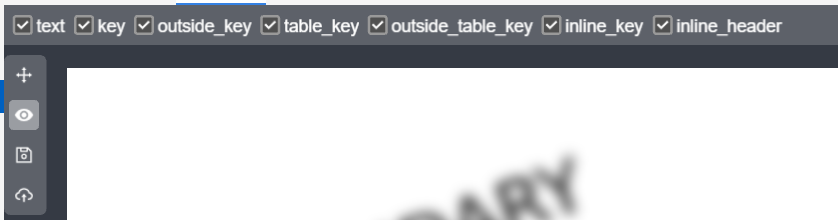
对测试结果的展示进行控制,下面是术语对应关系
| name | 描述 |
|---|---|
| text | 词块 |
| key | key的抽取(包括线) |
| outside_key | outside key的抽取(包括线) |
| table_key | table key的抽取(包括线) |
| outside_table_key | outside table key的抽取(包括线),通常是分析出的table key,但是不参与结果的输出 |
| inline_key | inline key的抽取(包括外边框) |
| inline_header | inline key对应行内抽取到值,鼠标悬浮会有维度区域的边框提示 |
保存
保存本地。
上传
上传到服务器,作为静态资源,用于编写工作流。
右侧栏
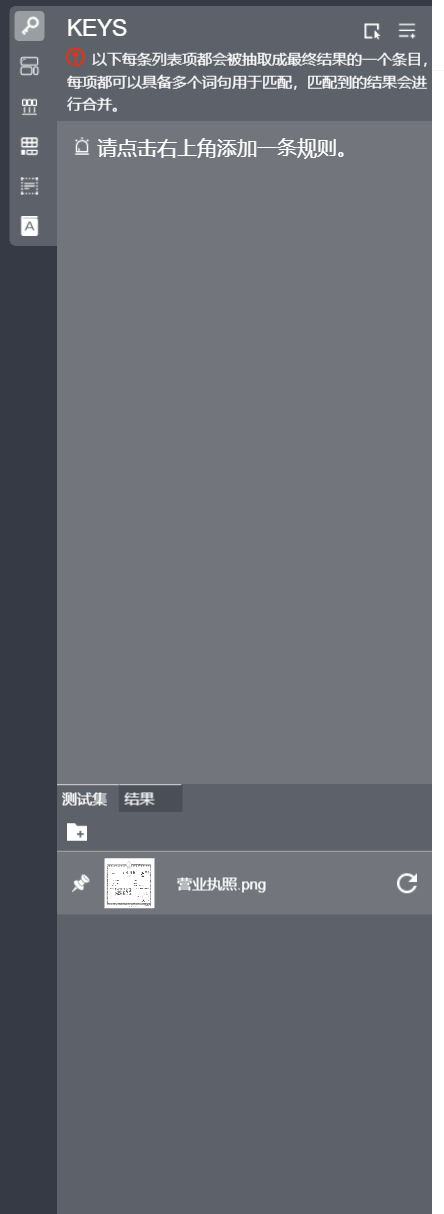
上边栏
主要用于标注配置,详细使用参考标注细则。
下边栏
- 测试集用于上传新的样本进行测试,右击样本可删除,点击右侧刷新按钮对该样本进行抽取测试。
- 结果用于查看当前样本的抽取结果。
2. 标注

1. KEY
key的配置按钮在右侧栏-上边栏的第一个按钮,key可以简单理解为通用的排版信息,通常是样本间的交集,例如下面的"名称"。添加一个key可以通过点击下图演示的按钮进行框选或者点击右侧的按钮手动输入,确认的输入会被作为一个 目标键进行多项匹配,也就是说key可以有多个匹配项进行匹配,匹配到的所有结果最后会进行合并,如果需要最终抽取结果的json的键为name,那么此时输入的应为name,同时把"名称"添加到name的匹配项。

可以点击第二个按钮查看并编辑已有的所有匹配项,可以看出刚刚勾选的同时添加到匹配项后,"名称"也被添加到这里了。同时也可以在点左侧的按钮进行新增匹配项。
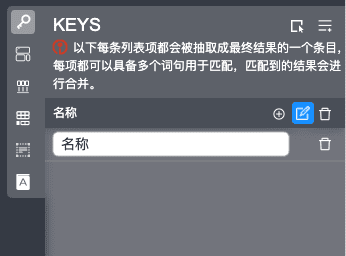
这时已经可以完成了标注的第一步,这时可以进行测试,点击测试集里对应样本的测试按钮后可以看出当前的结果。
可以看出来,此时抽取器对排版的理解很差,名称对应的值被联想到了很多错误的词块(在图中显示为连线,例如名称块连线到了右侧以及上下的很多词块,具体的可以点击结果查看当前样本的抽取结果)。 此时需要做的就是完善对样本的配置,优化抽取器对样本排版的理解。
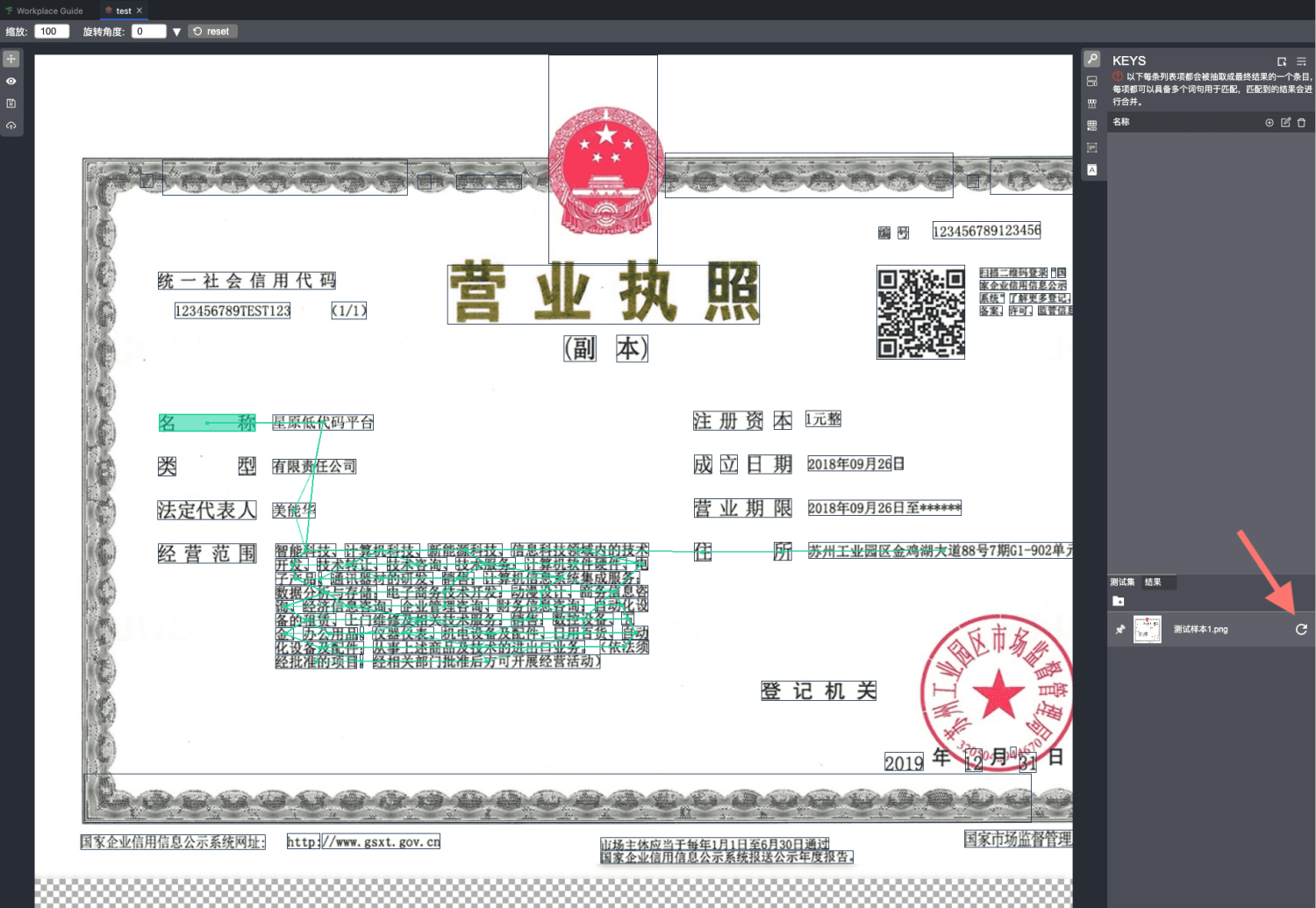
经过下面的配置,对比下可以看出一些抽取器的工作原理,此时的抽取器对排版的理解已经比较完善,抽取的结果也比较合理。
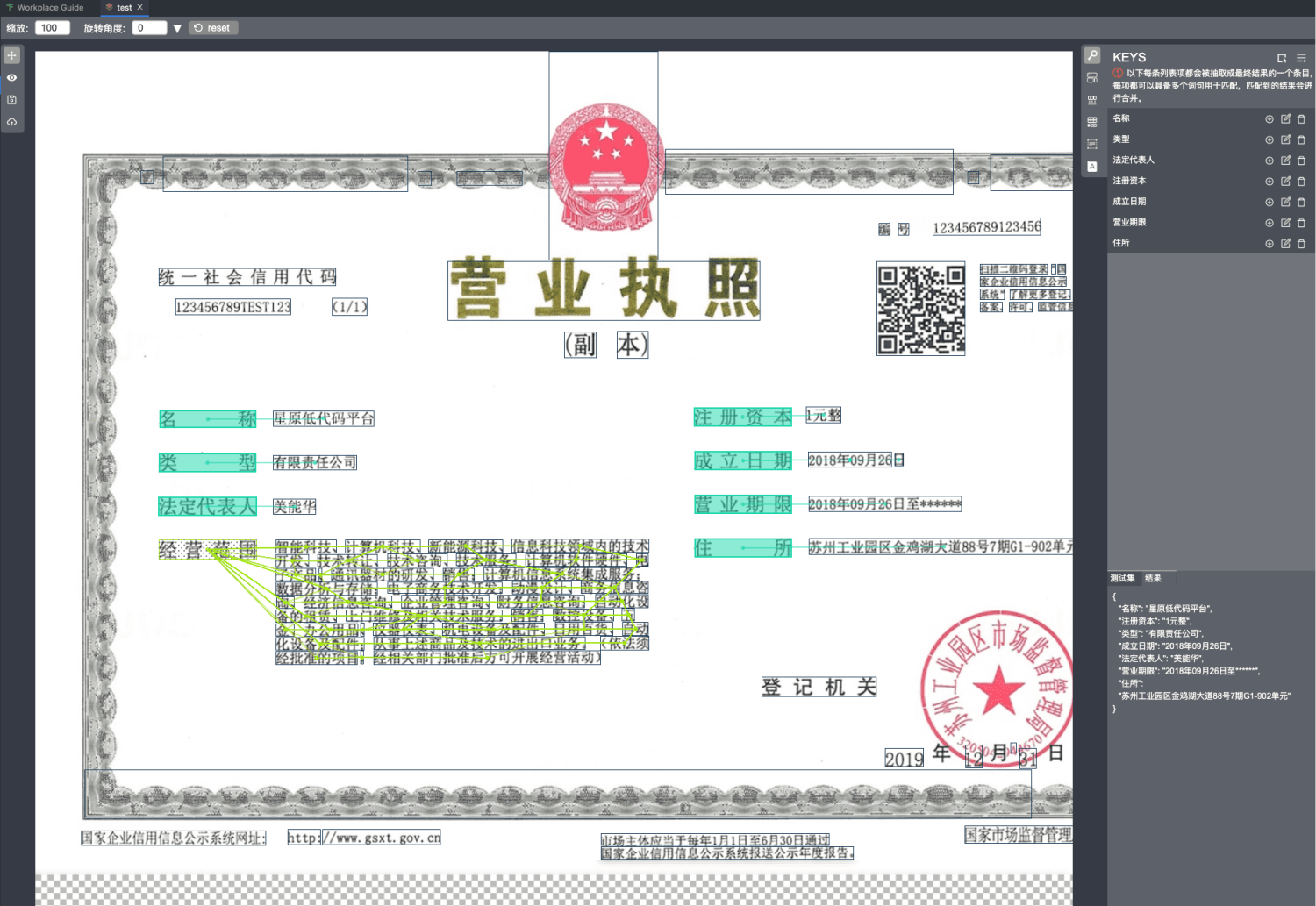
2. OUTSIDE_KEY
outside key的配置按钮在右侧栏-上边栏的第二个按钮,它的工作原理和key类似,不同的地方在于它虽然参与排版的分析,却不作为抽取结果进行输出,因此他没有匹配项的配置,添加的值直接作为匹配项参与抽取。可以看上图的"经营范围"便是outside key。
虽然outside key不参与结果输出,却在分析排版的过程中有着至关重要的作用。例如上图的"经营范围"如果不进行标注,"法定代表人"的抽取很可能会出现错误的联想(在图上显示为连线)。具体可以参考标注第一步的图片进行理解。
3. TABLE_KEY
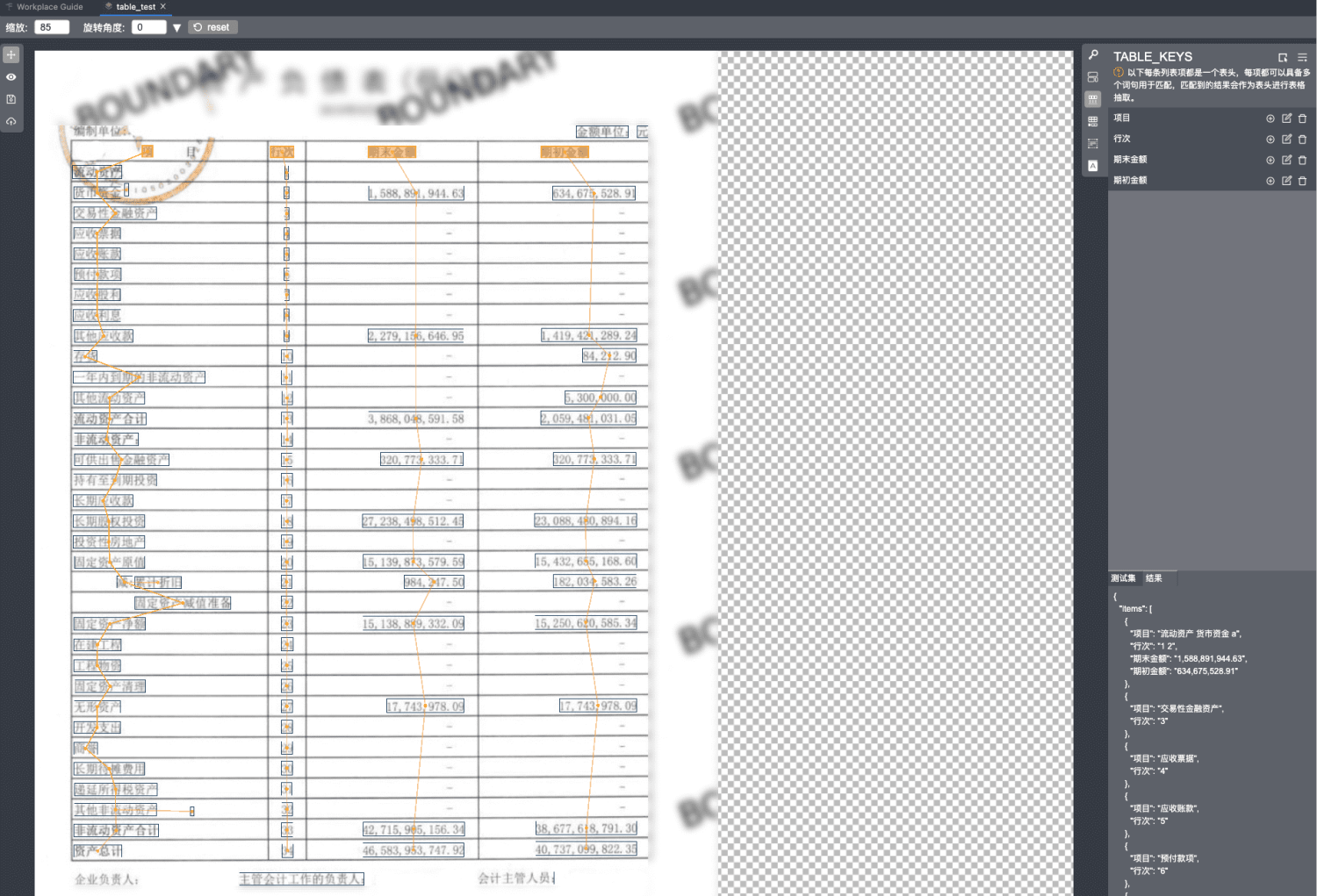
table key的配置按钮在右侧栏-上边栏的第三个按钮,它的配置方法与key类似。它是为了解决表格的抽取,需要标注的对象是表头,和key一样,他也有一对多的匹配项配置,匹配到的表头会进行纵向联想,最终输出到结果的items,如下图。
4. INLINE_KEY
inline key的配置按钮在右侧栏-上边栏的第四个按钮,不具有匹配项。此配置是为了解决不具备表格结构意义的扩展行,例如上图表格的虚线下的"资产总计"行,这行应该是对表格的期末金额与期初金额进行合计的,不具有我们配置的表格结构化信息。 把"资产总计"配置为inline key会使其成为单独的一个维度并进行抽取,最终输出到结果的inline。例如下图,可以看出"资产总计"被抽取到inline下,并且其键为纵向的表头。 可以把鼠标悬浮到红色块上查看inline key对应的行内的该值对应的表格维度区域,下图便是把鼠标悬浮在"34"该词块,纵向便会出现该维度的抽取区域,看下图可以推断出"34"对应的表格维度是我们配置的table key:行次。这也与最终抽取结果相对应。
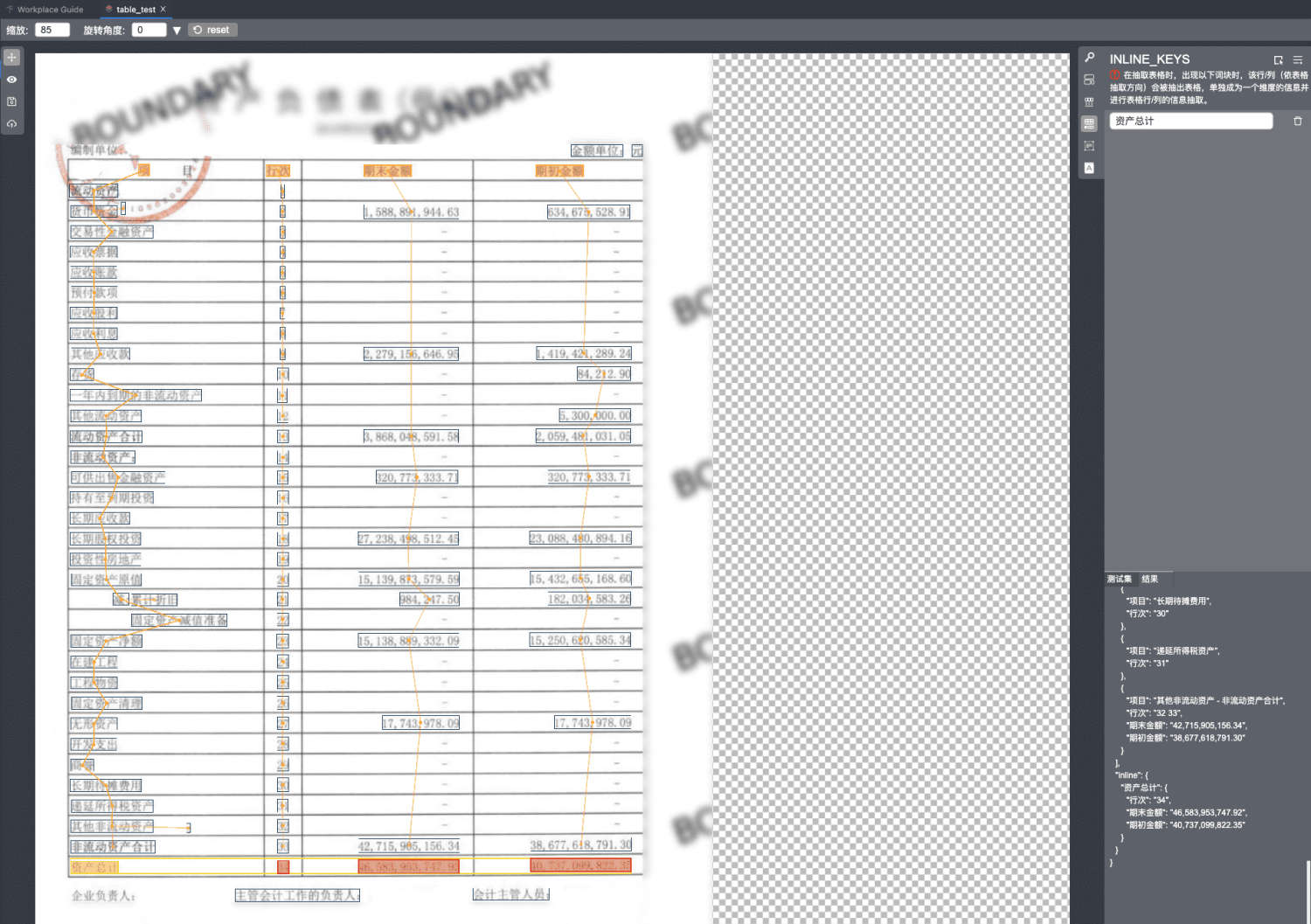
5. BOUNDARY
boundary的配置按钮在右侧栏-上边栏的第五个按钮。可以配置抽取的边界,left左边界,top上边界,right右边界,bottom下边界,每个边界都可以配置多个词块进行匹配,超出边界的部分不会进行任何抽取(边界部分在图片上会进行模糊处理并附加水印)。细心的读者可能会发现table key配置的图片 和inline key配置的图片上方的边界不相同,这是因为把"编制单位L"添加到了上边界,这也是为了限制表格的边界进行的配置,以阻止表格值的过度联想。
6. WORD
word的配置按钮在右侧栏-上边栏的第六个按钮。可以配置附加的词块合并规则,该配置可以用于弥补抽取器根据位置信息进行ocr结果合并词块的不足。例如两个字间距很大却有明显的词意义,可以将它添加到该配置。